Securing AI Applications in Go: From Prompt Injection to Data Privacy
Securing AI Applications in Go: From Prompt Injection to Data Privacy...
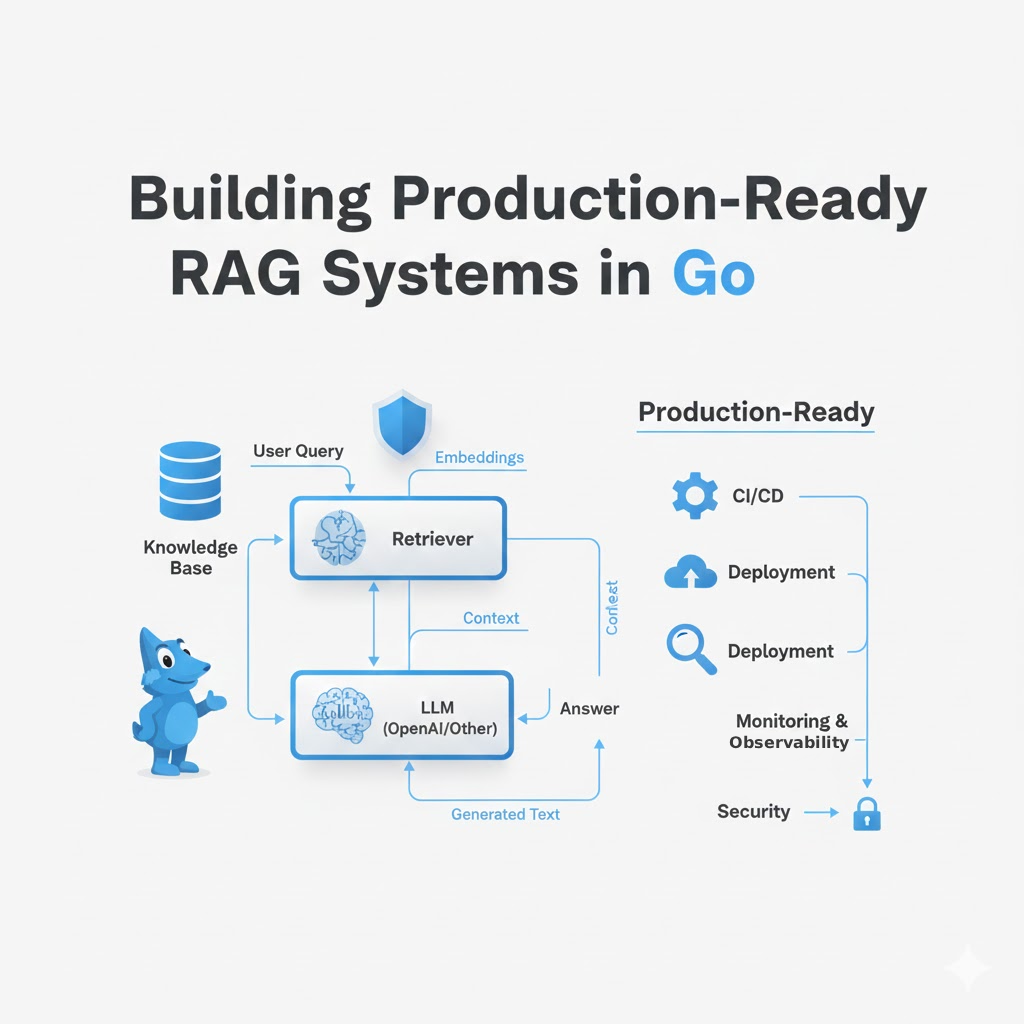
Retrieval-Augmented Generation (RAG) has become the go-to architecture for building AI applications that need to access external knowledge. While Python dominates the AI tooling landscape, Go offers compelling advantages for production RAG systems: superior performance, built-in concurrency, small memory footprint, and excellent deployment characteristics.
In this guide, we'll explore how to build a production-ready RAG system in Go, covering everything from core data structures to deployment considerations.
Before diving into implementation, let's understand why Go makes sense for RAG systems:
A production RAG system consists of several key components:
User Query → Query Processing → Vector Search → Context Ranking → LLM Generation → Response
↓ ↓
Document Pipeline Vector Database
Let's start with the foundational data structures for our RAG system:
package rag
import (
"context"
"time"
)
// Document represents a source document in the RAG system
type Document struct {
ID string `json:"id"`
Content string `json:"content"`
Metadata map[string]any `json:"metadata"`
Source string `json:"source"`
CreatedAt time.Time `json:"created_at"`
UpdatedAt time.Time `json:"updated_at"`
}
// Chunk represents a processed chunk of a document
type Chunk struct {
ID string `json:"id"`
DocumentID string `json:"document_id"`
Content string `json:"content"`
Embedding []float32 `json:"embedding,omitempty"`
Position int `json:"position"`
Metadata map[string]any `json:"metadata"`
TokenCount int `json:"token_count"`
}
// SearchResult represents a retrieved chunk with relevance score
type SearchResult struct {
Chunk *Chunk `json:"chunk"`
Score float32 `json:"score"`
Rank int `json:"rank"`
}
// RAGRequest encapsulates a user query
type RAGRequest struct {
Query string `json:"query"`
TopK int `json:"top_k"`
Filters map[string]any `json:"filters,omitempty"`
Context context.Context `json:"-"`
}
// RAGResponse contains the generated response and sources
type RAGResponse struct {
Answer string `json:"answer"`
Sources []SearchResult `json:"sources"`
Latency time.Duration `json:"latency"`
TokensUsed int `json:"tokens_used"`
}
The ingestion pipeline is critical for RAG quality. Here's a robust implementation:
// DocumentProcessor handles document ingestion and chunking
type DocumentProcessor struct {
chunkSize int
chunkOverlap int
embedder Embedder
vectorStore VectorStore
}
func NewDocumentProcessor(chunkSize, overlap int, embedder Embedder, store VectorStore) *DocumentProcessor {
return &DocumentProcessor{
chunkSize: chunkSize,
chunkOverlap: overlap,
embedder: embedder,
vectorStore: store,
}
}
// ProcessDocument handles the complete document processing pipeline
func (dp *DocumentProcessor) ProcessDocument(ctx context.Context, doc *Document) error {
// 1. Chunk the document
chunks := dp.chunkDocument(doc)
// 2. Generate embeddings in parallel
if err := dp.generateEmbeddings(ctx, chunks); err != nil {
return fmt.Errorf("embedding generation failed: %w", err)
}
// 3. Store in vector database
if err := dp.vectorStore.UpsertChunks(ctx, chunks); err != nil {
return fmt.Errorf("vector store upsert failed: %w", err)
}
return nil
}
// chunkDocument splits a document into overlapping chunks
func (dp *DocumentProcessor) chunkDocument(doc *Document) []*Chunk {
content := doc.Content
chunks := make([]*Chunk, 0)
position := 0
for i := 0; i < len(content); i += (dp.chunkSize - dp.chunkOverlap) {
end := i + dp.chunkSize
if end > len(content) {
end = len(content)
}
chunk := &Chunk{
ID: fmt.Sprintf("%s_chunk_%d", doc.ID, position),
DocumentID: doc.ID,
Content: content[i:end],
Position: position,
Metadata: doc.Metadata,
}
chunks = append(chunks, chunk)
position++
if end >= len(content) {
break
}
}
return chunks
}
// generateEmbeddings creates embeddings for chunks in parallel
func (dp *DocumentProcessor) generateEmbeddings(ctx context.Context, chunks []*Chunk) error {
const batchSize = 10
errChan := make(chan error, len(chunks))
semaphore := make(chan struct{}, batchSize)
var wg sync.WaitGroup
for _, chunk := range chunks {
wg.Add(1)
go func(c *Chunk) {
defer wg.Done()
semaphore <- struct{}{}
defer func() { <-semaphore }()
embedding, err := dp.embedder.Embed(ctx, c.Content)
if err != nil {
errChan <- err
return
}
c.Embedding = embedding
}(chunk)
}
wg.Wait()
close(errChan)
if err := <-errChan; err != nil {
return err
}
return nil
}
Define clean interfaces for vector storage and retrieval:
// VectorStore defines the interface for vector database operations
type VectorStore interface {
UpsertChunks(ctx context.Context, chunks []*Chunk) error
Search(ctx context.Context, query []float32, topK int, filters map[string]any) ([]SearchResult, error)
Delete(ctx context.Context, documentID string) error
HealthCheck(ctx context.Context) error
}
// Embedder defines the interface for generating embeddings
type Embedder interface {
Embed(ctx context.Context, text string) ([]float32, error)
EmbedBatch(ctx context.Context, texts []string) ([][]float32, error)
Dimensions() int
}
The orchestrator ties everything together:
// RAGSystem orchestrates the complete RAG pipeline
type RAGSystem struct {
embedder Embedder
vectorStore VectorStore
llmClient LLMClient
processor *DocumentProcessor
}
func NewRAGSystem(embedder Embedder, store VectorStore, llm LLMClient) *RAGSystem {
return &RAGSystem{
embedder: embedder,
vectorStore: store,
llmClient: llm,
processor: NewDocumentProcessor(512, 50, embedder, store),
}
}
// Query processes a RAG query end-to-end
func (rs *RAGSystem) Query(ctx context.Context, req *RAGRequest) (*RAGResponse, error) {
start := time.Now()
// 1. Embed the query
queryEmbedding, err := rs.embedder.Embed(ctx, req.Query)
if err != nil {
return nil, fmt.Errorf("query embedding failed: %w", err)
}
// 2. Search vector store
results, err := rs.vectorStore.Search(ctx, queryEmbedding, req.TopK, req.Filters)
if err != nil {
return nil, fmt.Errorf("vector search failed: %w", err)
}
// 3. Build context from results
context := rs.buildContext(results)
// 4. Generate response with LLM
answer, tokens, err := rs.llmClient.Generate(ctx, req.Query, context)
if err != nil {
return nil, fmt.Errorf("LLM generation failed: %w", err)
}
return &RAGResponse{
Answer: answer,
Sources: results,
Latency: time.Since(start),
TokensUsed: tokens,
}, nil
}
// buildContext constructs the context string from search results
func (rs *RAGSystem) buildContext(results []SearchResult) string {
var builder strings.Builder
builder.WriteString("Use the following context to answer the question:\n\n")
for i, result := range results {
builder.WriteString(fmt.Sprintf("Source %d (relevance: %.2f):\n", i+1, result.Score))
builder.WriteString(result.Chunk.Content)
builder.WriteString("\n\n")
}
return builder.String()
}
type RetryConfig struct {
MaxAttempts int
InitialDelay time.Duration
MaxDelay time.Duration
Multiplier float64
}
func withRetry(ctx context.Context, cfg RetryConfig, fn func() error) error {
delay := cfg.InitialDelay
for attempt := 0; attempt < cfg.MaxAttempts; attempt++ {
if err := fn(); err == nil {
return nil
} else if !isRetryable(err) {
return err
}
select {
case <-ctx.Done():
return ctx.Err()
case <-time.After(delay):
delay = time.Duration(float64(delay) * cfg.Multiplier)
if delay > cfg.MaxDelay {
delay = cfg.MaxDelay
}
}
}
return fmt.Errorf("max retry attempts exceeded")
}
type Metrics struct {
QueryLatency prometheus.Histogram
EmbeddingLatency prometheus.Histogram
SearchLatency prometheus.Histogram
LLMLatency prometheus.Histogram
ErrorCount prometheus.Counter
RequestCount prometheus.Counter
}
func (rs *RAGSystem) QueryWithMetrics(ctx context.Context, req *RAGRequest) (*RAGResponse, error) {
rs.metrics.RequestCount.Inc()
start := time.Now()
response, err := rs.Query(ctx, req)
if err != nil {
rs.metrics.ErrorCount.Inc()
return nil, err
}
rs.metrics.QueryLatency.Observe(time.Since(start).Seconds())
return response, nil
}
type CachedRAGSystem struct {
*RAGSystem
cache Cache
ttl time.Duration
}
func (crs *CachedRAGSystem) Query(ctx context.Context, req *RAGRequest) (*RAGResponse, error) {
cacheKey := fmt.Sprintf("rag:%s", hashQuery(req))
// Check cache
if cached, found := crs.cache.Get(cacheKey); found {
return cached.(*RAGResponse), nil
}
// Execute query
response, err := crs.RAGSystem.Query(ctx, req)
if err != nil {
return nil, err
}
// Cache result
crs.cache.Set(cacheKey, response, crs.ttl)
return response, nil
}
func TestRAGSystem(t *testing.T) {
// Use test doubles
mockEmbedder := &MockEmbedder{}
mockStore := &MockVectorStore{}
mockLLM := &MockLLMClient{}
system := NewRAGSystem(mockEmbedder, mockStore, mockLLM)
t.Run("successful query", func(t *testing.T) {
ctx := context.Background()
req := &RAGRequest{
Query: "What is RAG?",
TopK: 5,
}
mockEmbedder.On("Embed", ctx, req.Query).Return([]float32{0.1, 0.2}, nil)
mockStore.On("Search", ctx, mock.Anything, 5, mock.Anything).Return([]SearchResult{}, nil)
mockLLM.On("Generate", ctx, mock.Anything, mock.Anything).Return("RAG is...", 100, nil)
response, err := system.Query(ctx, req)
assert.NoError(t, err)
assert.NotNil(t, response)
assert.Greater(t, response.TokensUsed, 0)
})
}
For production deployment, consider this architecture:
┌─────────────┐
│ Load │
│ Balancer │
└──────┬──────┘
│
┌───┴────┐
│ API │ ← Go RAG Service (multiple instances)
│ Gateway│
└───┬────┘
│
┌───┴─────────────────┐
│ │
┌──▼───────┐ ┌─────▼──────┐
│ Vector │ │ LLM │
│ DB │ │ Service │
│(Pinecone/│ │ (OpenAI) │
│ Weaviate)│ └────────────┘
└──────────┘
Building production-ready RAG systems in Go offers significant advantages in performance, reliability, and operational simplicity. The combination of strong typing, excellent concurrency primitives, and efficient resource utilization makes Go an excellent choice for RAG deployments at scale.
The data structures and patterns outlined here provide a solid foundation for building robust RAG systems. Remember to focus on observability, error handling, and testing to ensure your system performs reliably in production.
Happy building!


